Kirjoitus käy läpi miten hakea Wikisanakirjasta suomen kielen verbejä. Sanojen hakeminen tehdään Pharo kielellä. Artikkelin lopputulos on kolme tiedostoa, jokaisessa tiedostossa on oman sanaluokan sanat. Yksi sana per rivi.
Pharossa on jo valmiiksi Zinc-niminen paketti, jolla voi ladata verkkosivujen sisällön. Suomen kielen verbit löytyvät osoitteesta https://fi.wiktionary.org/w/index.php?title=Luokka:Suomen_kielen_verbit. Aloitussivu näyttää selaimella tältä:
Sivun sisällön saa Pharo-ympäristöön seuraavalla komennolla:
"sivusto_raw := 'https://fi.wiktionary.org/w/index.php?title=Luokka:Suomen_kielen_verbit&from=A' asUrl retrieveContents."
Kyseinen komento tallentaa muuttujaan: sivusto_raw yllä näkyvän sisällön html-muodossa.
Jotta tekstistä olisi helpompi etsiä haluamamme sanat, tallennetaan verkkosivun lähdekoodi puu-tietorakenteeseen. Tätä vaihetta varten pitää ladata erillinen paketti "XPath". Paketin saa ladattua ajamalla komennon
Metacello new
baseline: 'XPath';
repository: 'github://pharo-contributions/XML-XPath/src';
load.
Kun paketti on saatu ladattua, sitä käytetään html-koodin puhtaasta tekstistä muuttamiseksi jäsenneltyyn puu-muotoon komennolla:
"tree := (XMLDOMParser parse: sivusto_raw) document."
Tämän jälkeen tree muuttujasta voi hakea tiettyjä elementtejä helpommin kuin pelkästä tekstistä hakiessa(Antaisiko tästä tarkemman esimerkin?). Tätä varten tarvitsee tietää, minkä elementin sisällä verbit ovat. Katsotaan nettisivulta, missä elementissä verbit sijaitsevat. Klikataan hiiren oikealla listan ensimmäistä verbiä (aaduttaa) ja valitaan vaihtoehto "Inspect Element (Q)".
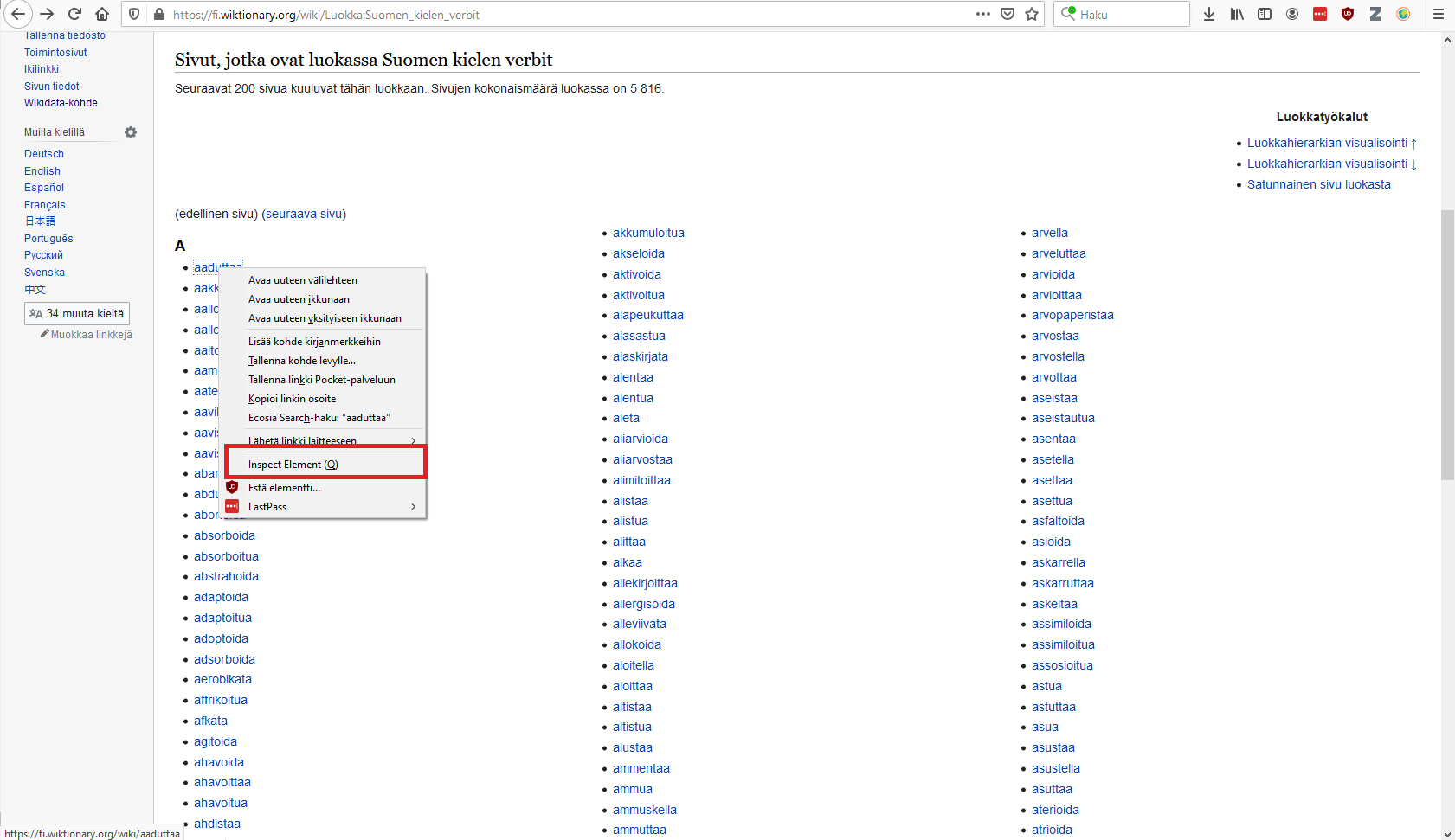
Tämän jälkeen selaimen alareunaan tulee ikkuna, jossa näkyy sivun sisältö tekstimuodossa. Alla olevassa kuvassa sinisellä korostettu rivi kertoo kohdan, jota klikkasimme näytöllä hiiren oikealla painikkeella.
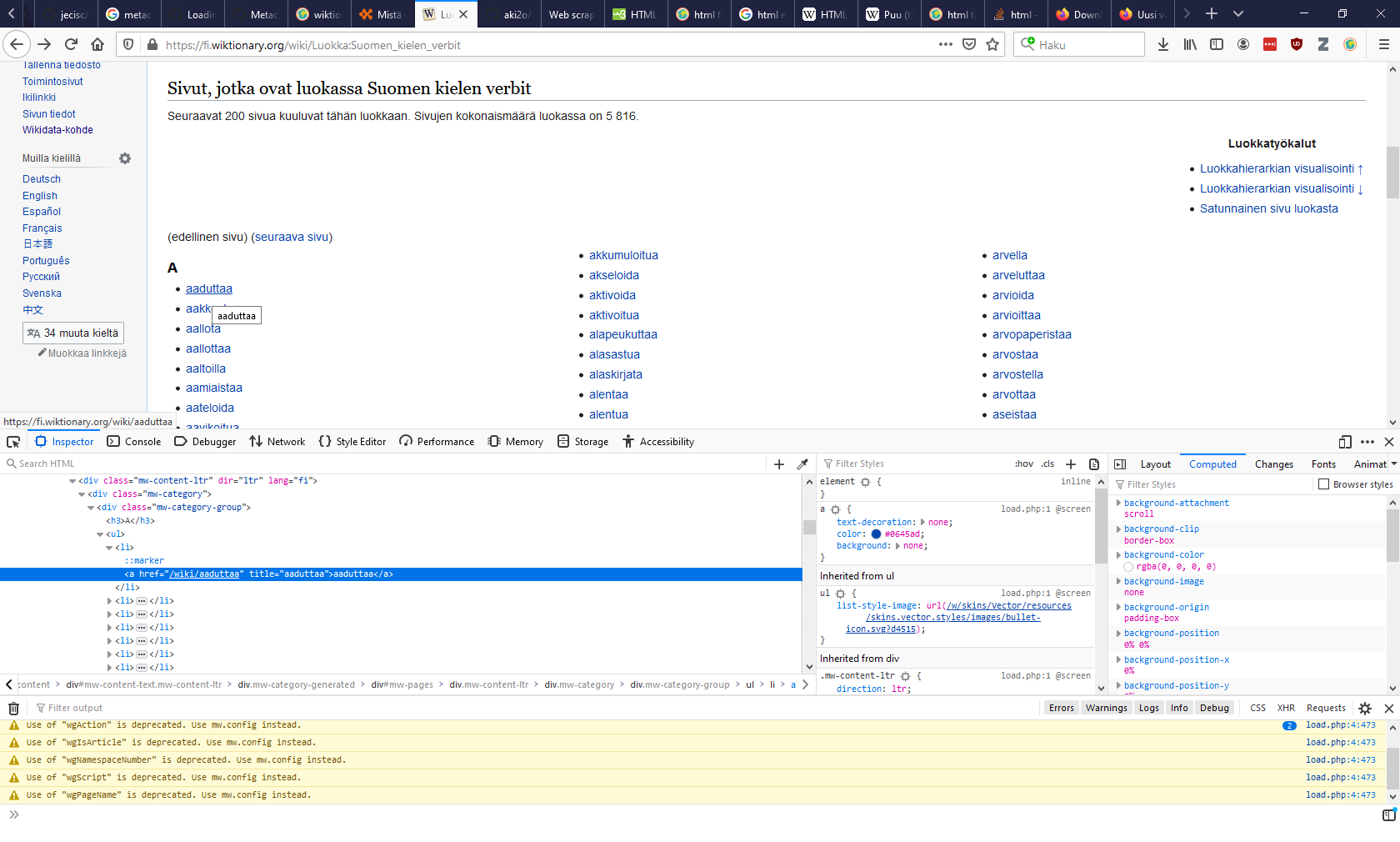
Kun hiiren vie korostetun rivin päälle, näkee yläpuolella ikkunassa, mitä aluetta sivulla kyseinen tekstinpätkä edustaa.
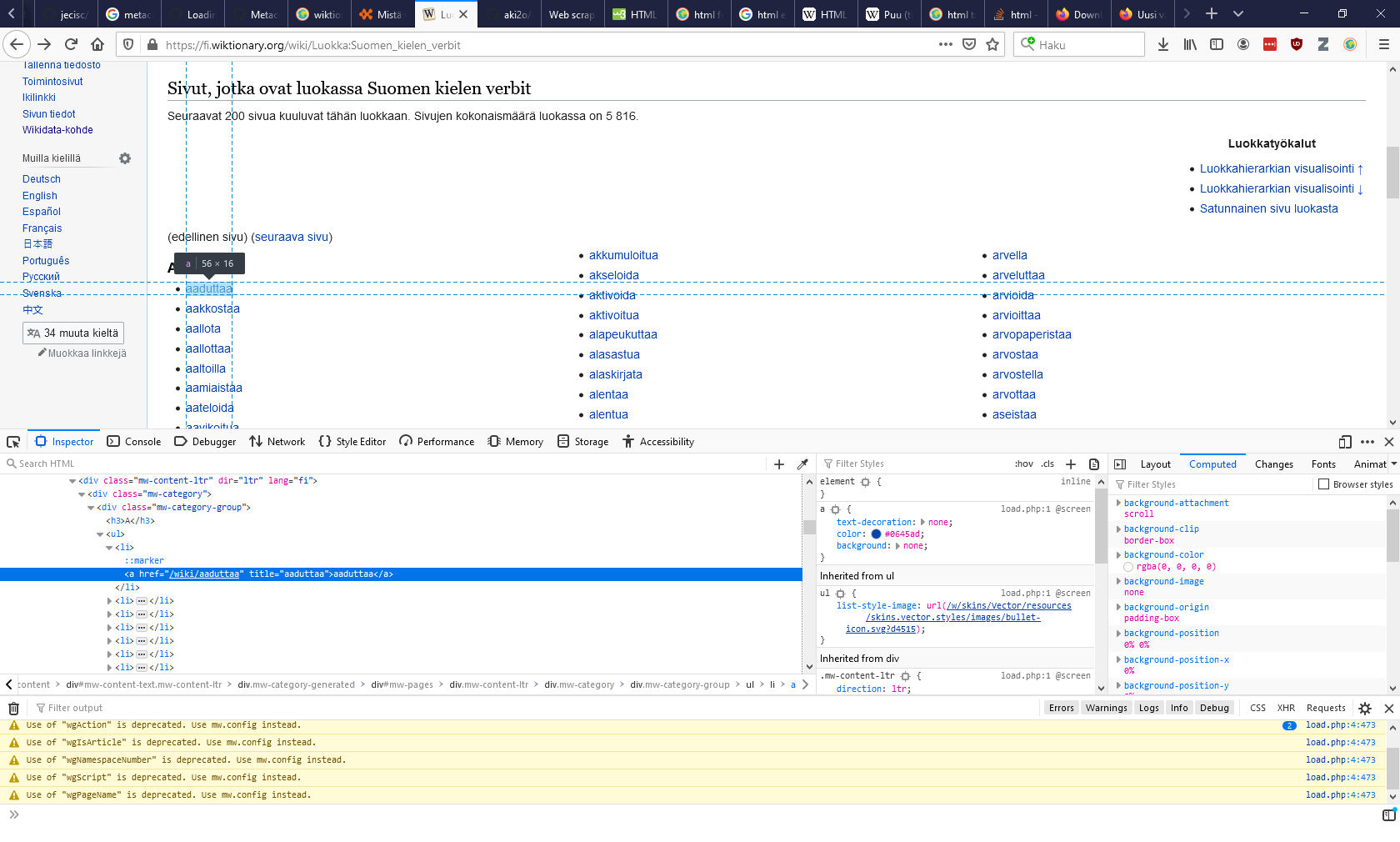
Kun hiiren vie hieman ylemmäs, "mw-category-group"-rivin päälle, huomaa, että kaikki verbit on korostettu sinisellä:
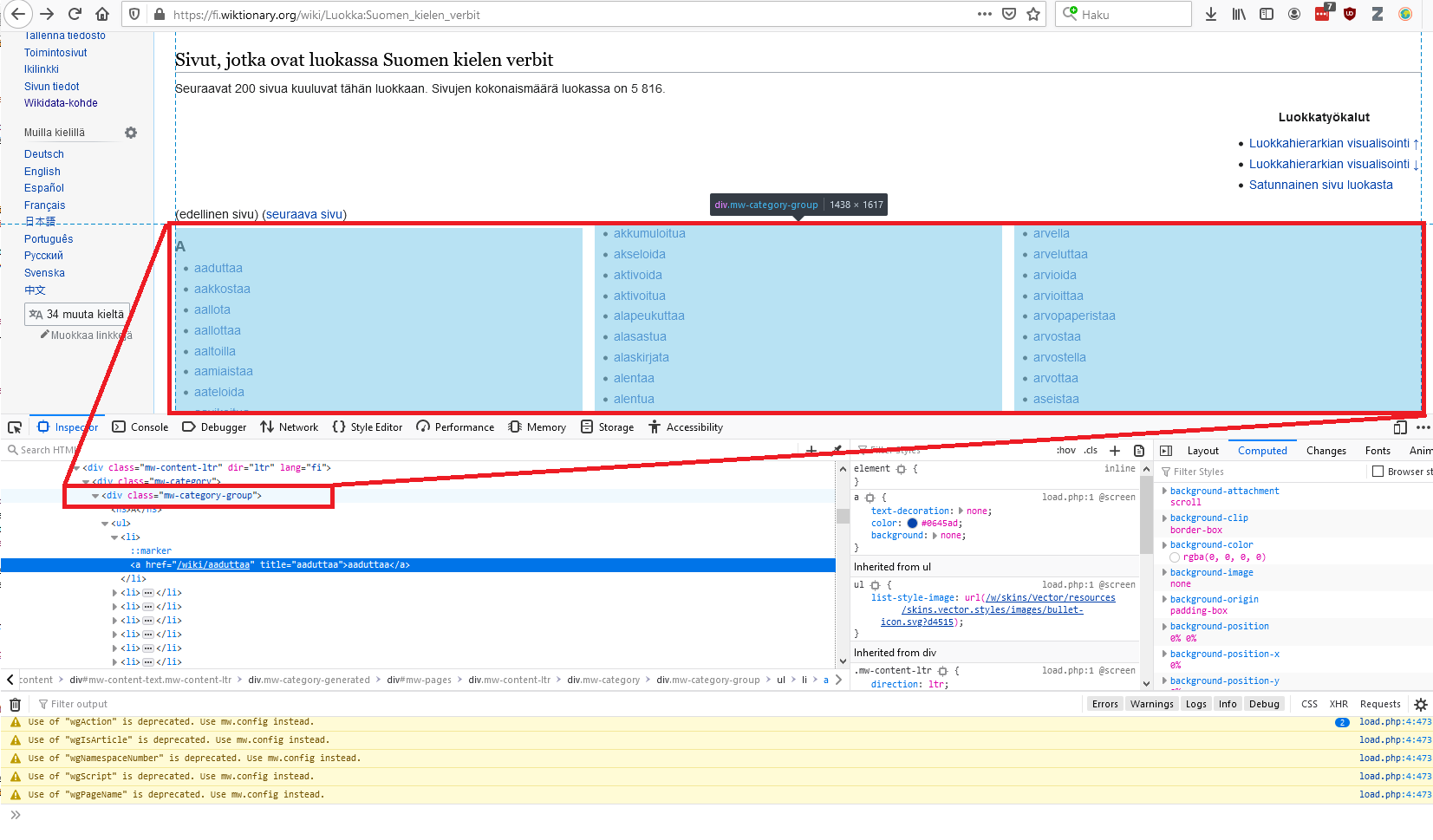
Eli elementti <div class="mw-category-group"> sisältää haluamamme tekstit. Tavoitteena on siis valita ohjelmoimalla kyseinen elementti. Kyseinen elementti saadaan ajamamma komento:
"verbilistat := tree xpath: '//div[@class="mw-category-group"]'."
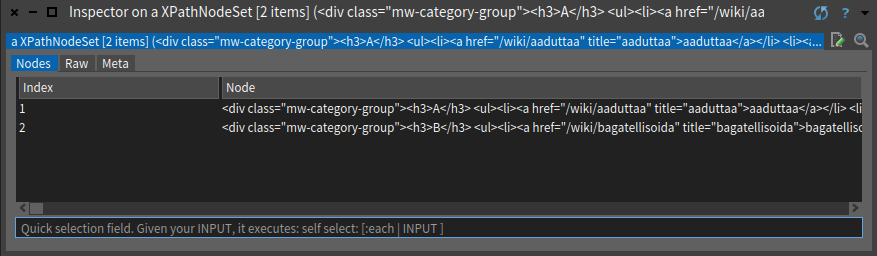
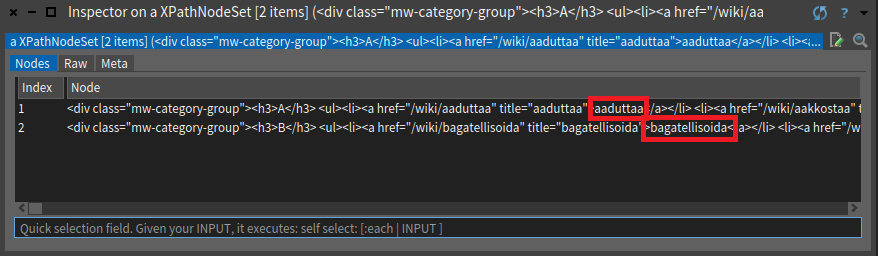
Kun muuttujaa verbilistat tarkastelee (inspect) Pharossa. Huomaa, että se sisältää kaksi elementtiä. Toinen elementti sisältää A:lla alkavat verbit ja toinen B:llä alkavat.
Lopulta haluamme ainoastaan <a> -elementtien tekstisisällöt:
"verbit_1 := tree xpath: '//div[@class="mw-category-group"]//li//a/text().'". Kyseinen komento tallentaa verbit muuttujaan verbit_1. Kun muuttujaa tarkastelee Pharossa, näkee muuttujan sisältävän verbejä:
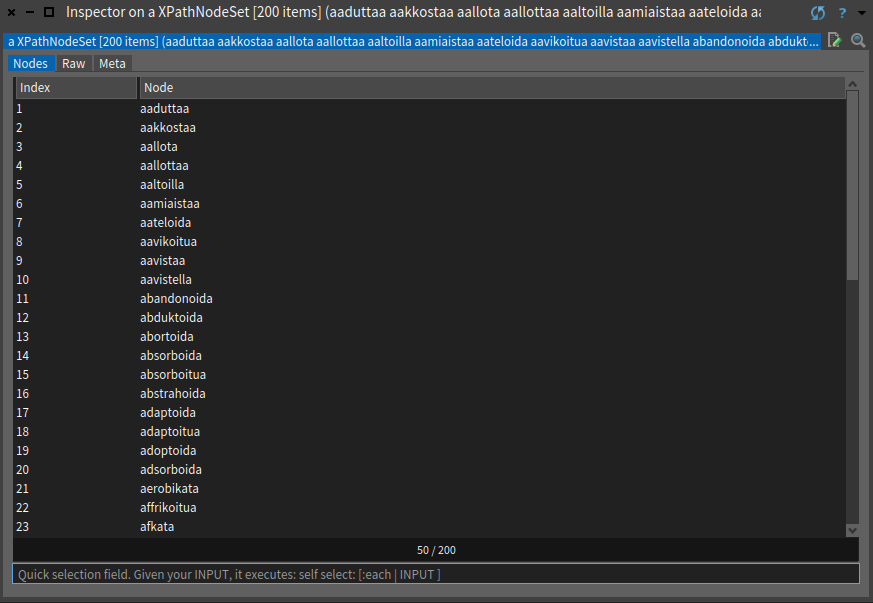
Nyt on saatu ensimmäisen sivun verbit tallennettua muuttujaan!
Jotta voidaan ladata seuraavan sivun lähdekoodi käsiteltäväksi, tulee tietää, missä linkki seuraavalle sivulle sijaitsee. "Seuraava sivu" -painike tulee verbien jälkeen. Tässä voi käyttää samaa "Inspect Element" -komentoa kuin aiemmin. Haluamme saada alla olevan kuvan merkatun href-attribuutin arvon tallennettua muuttujaan.
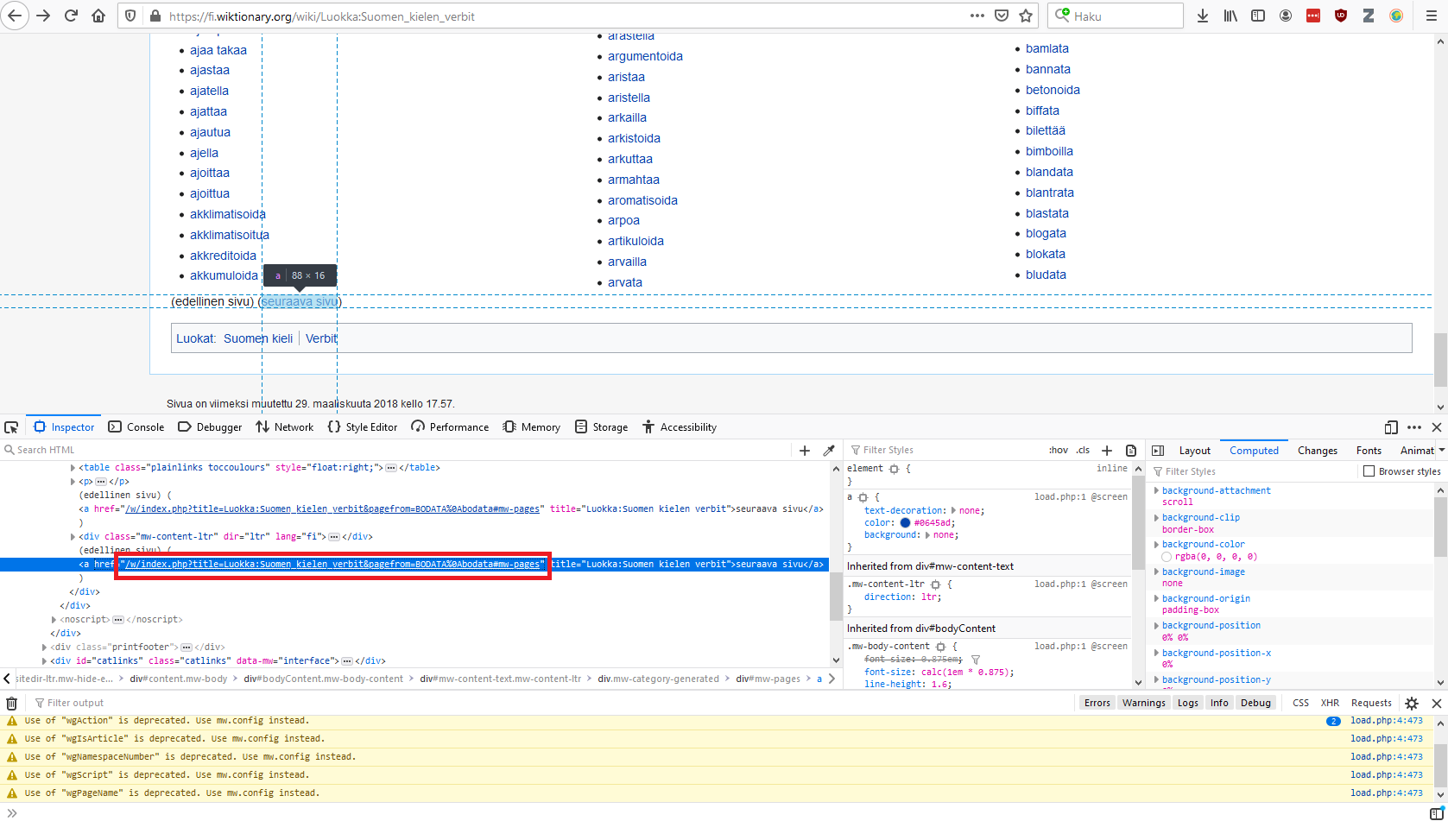
Se onnistuu komennolla "nextPagePath := tree xpath: 'string((//div[@id="mw-pages"]/a[text()="seuraava sivu"])[1]/@href)'."
href-attribuutti sisältää ainoastaan linkin loppuosan, joten siihen täytyy lisätä linkin alkuosa "https://fi.wiktionary.org". Tämä tehdään komennolla "nextPageUrl := ('https://fi.wiktionary.org' , nextPagePath) asUrl." komennon loppuosa "asUrl" muuttaa linkin tekstimuodosta Url-datatyypiksi. Tämän jälkeen täytyy vielä poistaa linkin loppuosa "#mw-pages" komennolla "nextPageUrl fragment: nil.", koska se jostain syystä aiheuttaa virheen nettisivun lähdekoodia haettaessa.
Seuraavan sivun verbit saa toistamalla yllä kuvatut vaiheet juuri äsken luomallamme linkillä, joka on muuttujassa nextPageUrl